OS Notes
OS
Address Spaces and memory management
Address space is an easy to use abstraction of the physical memory. It contains the memory state of the current program. A usual program has a stack, heap and a code section in the memory. The abstraction also helps in virtualizing memory, i.e., the processes might not actually be in the pages they think they are, which provides more security. Therefore, each process operates on NOT physical address but virtual address.
Major goals of virtual memory:
- efficiency: translation should be fast and efficient
- transparency: the program shouldn't know or care it's running in virtual mode
- protection: no read-write of pages between processes without explicit permission from the process.
Types of memory
- We have stack memory, that, well, acts like a stack. Used for function calls and shit.
- Heap memory, manipulated by
mallocandfree. They manipulate usingbrk,sbrk, andmmap. - Code section, keeping the instructions of the binary.
- Global vars, constants, and other lookup shit.
Address Translation
We need hardware support for this. The MMU converts every virtual address to a physical address and that is done via page tables set up by the operating system.
We take a granular approach to discuss this:
- Simple: First Model
Assumptions:
- Contiguous physical memory.
- Address space less than the size of physical memory.
- Address spaces are the same size.
Here we can translate the process address space very easily. And also mitigate problems.
\[ phy = virt + base \]
\[ max\_addr = virt + bound \]
\[ min\_addr = virt \]
MMU also checks for the bounds of the process, in a sense that it keeps the maximum offset that process can go to.
The OS has to do a couple of things:
- Maintain a free list of segments that are free for putting a process page over there
- Clean upon a process being killed/terminated
- Save and restore the MMU data in the PCB along with the registers and other stuff
- Provide exception handlers to the hardware
- Segmentation: Second Model
We generalize the base-bound idea to be per logical-segment instead of per process. Here a logical segment would just be like a section of the binary we know, stack, heap, code, bss etc.
Translation scheme looks pretty much the same, but this time it's per segment instead of per process. Though the general bounds on the process still exist of course.
To know which address we are referring to, we can keep tag bits at the top of the virtual address that are read to determine the segment. This, however, limits the size of the addresses you can use. Another approach is to do it implicitly by noticing how the address was formed, for example, an address contained in the instruction pointer would mostly point to the code section.
Apart from base and bound, now it also needs to know which way a segment grows, so that bounds are actually set properly. This is done with another bit in MMU that tells the hardware that growth is positive or negative.
In addition, we can now share certain segments with other processes (code section of a library for example). This way, whatever is used by multiple processes only has one instance in memory. To support this, we need protection bits for the segment, so that segments that are shared are read-only. This way, we can share code segments and only have one physical instance in memory while also having multiple virtual instances, one per process that's running it.
For some cases it might be necessary to extend the segment beyond what it already has. In particular, this is true for heap. To do that, you need to have a syscall that extends or shrinks it. Linux has
brkandsbrk.Fragmentation is also a problem. If we do not have large contiguous chunks of memory free, we might not be able to allocate a new segment a chunk. One solution is to rearrange the chunks such that we have a large contiguous memory segment free. Once that happens, we also need to copy the memory chunks and free the existing ones. Apart from this, we also need to update the MMU regarding the new locations. Needless to say, it is very expensive, and consumes a lot of CPU power. Also, it makes using
brkandsbrkmuch harder as you need to rearrange chunks every single time.There are multiple algorithms to deal with the problem and all of them work well to a certain degree but none of them can evade the problem entirely.
Free Space management
If it's fixed size chunks then managing free memory is really easy. It's hard when you have variable sized units (happens with heap A LOT). The free space gets fragmented into multiple small chunks.
We study malloc and free and how they operate. We also work on the premise of no compaction,
and that is because once memory is handed out to a program it cannot be reclaimed before a
corresponding free is called.
A free list is a set of elements that describe the free space still remaining in the heap. Assume we have a 30 byte heap with the first and last 10 bytes free. A request for anything greater than 10 bytes will fail and anything equal to 10 bytes can be satisfied by either chunk.
If something smaller than 10 bytes is requested, the allocator splits the memory chunk and gives out the required memory to the process. A corollary mechanism is called coalescing which combines contiguous free chunks into one chunk.
Most allocators store a header along with the returned block that contains the information about size and other metadata.
For the actual implementation, we create a list in the memory where we are allocating. We take
an example of mmap that gives us a pointer to free space (raw free space).
void *mmap(void addr[.length], size_t len, int prot, int flags, int fd, off_t offset);
This is the signature of mmap on linux. If addr is NULL, then it chooses a page aligned
address. We assume that the other parameters are all fine, we have PROT_READ and PROT_WRITE
for protection. and anonymous and private mapping.
We use the length to be whatever we need, plus the size of the header field. We also have a
head pointer somewhere by the allocator that maintains the first free address in the entire
address space. The next pointer of that marks the next free block in memory, or NULL if the
node is the last one.
Let's say now that one of the chunks that was sandwiched in between two allocated chunks was freed. In such a case, you have to update the head to point to this now free chunk and its next pointer will be where the head originally was. This way, we have a fragmented heap.
After that, the order of freeing the chunks matters. If you free them in a random order, they will be a weird linked list that will point to each other with the head somewhere in the middle.
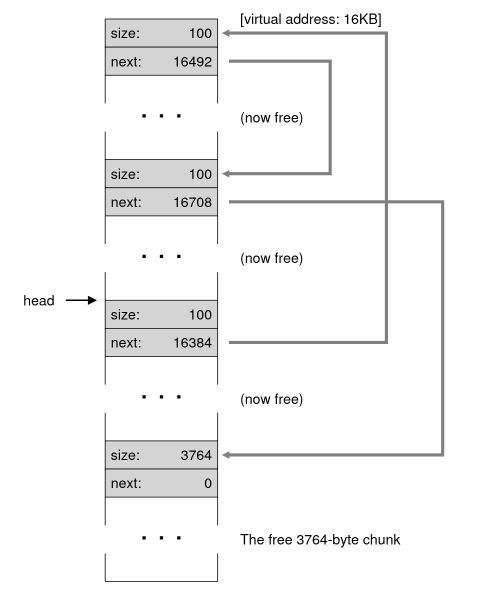
This is a problem since the heap is massively fragmented even though it shouldn't be. So we need to coalesce. Go through the list and merge neighbouring chunks, and the heap will be whole again.
Strategies for managing free space
All these algorithms suffer from the problem of scaling since searching lists can be quite slow.
- Best fit
Search through the free list until you get the closest chunk in terms of size. Takes too long to search the list though.
- Worst fit
Search the list to find the largest chunk. Use it to minimize fragmentation. Usually a bad algorithm.
- First fit
Find the first chunk that can satisfy it and return that. Usually leads to a lot of fragmentation in the earlier part of the list.
- Next fit
Like first fit, but keep a pointer to where you last searched. Reduces the fragmentation at the beginning of the list and keeps the allocations evenly distributed.
- Segregated lists
This already keeps a list of chunks you'd popularly need to service standard requests faster. If the specialized allocator is running low on space, it can request more from the general allocator, which provides it. If the specialized allocator has too many chunks and the general allocator needs to get a large chunk, it can also request some chunks from the specialized allocator.
- Buddy system
This is meant for coalescing easily since coealescing is a very important part of the heap. One example is the binary buddy allocator. Here the heap is thought of as a big space of \(2^N\). When memory is requested it divides it into half till the chunk size just fits the requirement. Since each block has a pair, you check the pair of the returned block for whether or not its free. If it is, then you coalesce them and keep going up till everything is coalesced or the adjacent block is in use.
Coalescing is easy because you only need to change one bit to find the buddy which is determined by the level in the tree you're at which in turn is determined by the size.
Paging
<- Relocations in ELFs <- Virtual memory in RISCV
We chop up memory into rigid fixed-size pieces. Each piece is called a page. This allows for flexibility as we don't need to do a lot of the book-keeping we don't need to make assumptions about how the binary will use the page.
To keep a track, we use a per-process data structure called page table that is maintained by the kernel. The generation and translation scheme is the same as that discussed in cs2600. They are not stored in the MMU like before but instead stored in the kernel virtual memory.
They can go to any depth of page tables, linear being the most simple in complexity.
TLBs and their role in OSes
We use translation lookaside buffers that store the last few page mappings and use it to generate frequently used mappings faster. This is a part of the chip's MMU and leads to tremendous speedup for the translation. We basically take the virtual address part from the virtual address (basically remove the offset bits) and XOR it with every entry in the TLB. If any of them is a zero, we have a hit, which implies that the translation is already present. Else we have a miss, in which case we need to do an address translation.
We raise a trap when a TLB miss happens in case of RISC architecture and CISC handles it entirely on its own based on some special registers. The trap generated by a TLB miss has to be handled separately than other traps. Other traps resume operations from the instruction after the one that generated the trap while this one resumes from the one that generated the trap. A TLB also has some metadata bits needed for the pages and other stuff.
- Context switching
When we change process, the TLB has to be changed. This is achieved by setting the valid bit of all entries to 0, so that the next cycle makes it a point to look into the page table. However, this can be very expensive in practice, and hence, it is problematic to do so. Hardware manufacturers support an additional ASID field that lets you store multiple translations along with which process they belong to.
Replacement policy can be any of LRU or random, which are the two common ones used.
Smaller tables
Page tables can take up a lot of space in memory. A simple method to make smaller page tables is to have larger page sizes. However, that leads to internal fragmentation as pages will have unused regions of memory inside them.
A simple solution is to increase the page size of the system. Doing so, however, leads to larger internal fragmentation in the pages.
Another approach is to use page and segments combined. Just like the MMU did, we store all the base + bounds + direction triplets in the table and use that during lookup to check for the proper section.
An even simple solution is multi-level page tables. Instead of having a giant array, we have a tree of tables with multiple levels of table lookup as we described in cs2600. That allows us to elide the construction of entire subtrees and thus saves a lot of space. It also makes the table as the same size as that of a page, simplifying memory management.
Another extreme example of this behaviour is inverted page tables. In this case we basically do a mapping from physical pages to virtual pages. This allows us to only have a finite sized page table at any point of time, and lets us save memory by doing so. However, since a linear lookup isn't very efficient, the systems utilizing this often use a hashmap to get that mapping.
Finally, we can also relax the condition that pages must necessarily be in the memory and swap inactive pages to the disk in a method called swapping.
Swapping Mechanisms and Policies
Swap is memory present on the disk that is used for storing the extra page tables. To support that, we first need the present bit to be supported in page tables. This indicates whether the page is present in memory or not.
Now, when the present bit is set to 0, we know that the page isn't present in the main memory and it leads to the hardware generating a page fault. The page fault handler loads the page from the disk, and during this time the process goes into a blocked state because of the disk I/O happening.
Once the page is loaded from memory, we update the page table entries and continue execution of the process. If the memory is full, then the OS picks a page it wants to remove.
Now the replacements themselves may happen when the OS wants them to. OS's have a low watermark and a high watermark. When we have fewer than LW pages left, the OS runs a background process that removes some of the memory pages such that atleast HW pages are free and goes to sleep.
The way in which we swap out the pages is called page replacement policy. The most optimal policy is basically impossible to implement. It evicts the page that will be used furthest in time.
Another example of a simple policy for page replacement is FIFO. It simply means that the page that came in the earliest should be the one that goes out first. Another very simple policy is replacing a page at random. The performances of these two is not very good for very obvious reasons.
The best method would be to take into account the history of the system. This is the principle behind LRU or Least Recently Used. This keeps in track the last usage of the page and evicts pages based on that.
There are a couple of methods to implement LRU practically. One of them is to have hardware support for having a time field in each of the pages. Later, the OS can just scan all the pages for the one with the least timestamp and evict it. Unfortunately, this leads to a lot of time spent in scanning pages as the number of pages grows.
There is a simple approximation to this as done in the linux kernel which is called as clock-pro. Clock-pro by itself has a lot of tweaks and patterns to make it way more efficient, but the basic idea remains the same as what is described below.
We have a use bit in the page metadata, that allows us to keep a track of when it was used last. We have a circular list with a clock hand that points at one entry. When a replacement has to occur, the OS checks if the use bit of the entry is set or not. If it's set, then it was recently used and thus shouldn't be evicted. This is now set to 0, and the clock hand continues forward till it finds a page with the bit set to 0 already.
Apart from all of this, OS's also use demand paging; a page is loaded into memory only when it's needed. Also, clustering of writes happens often, as that leads to better performance with lesser write overhead.
A complete Virtual Memory System
We study two examples: VAX and Linux.
- VAX
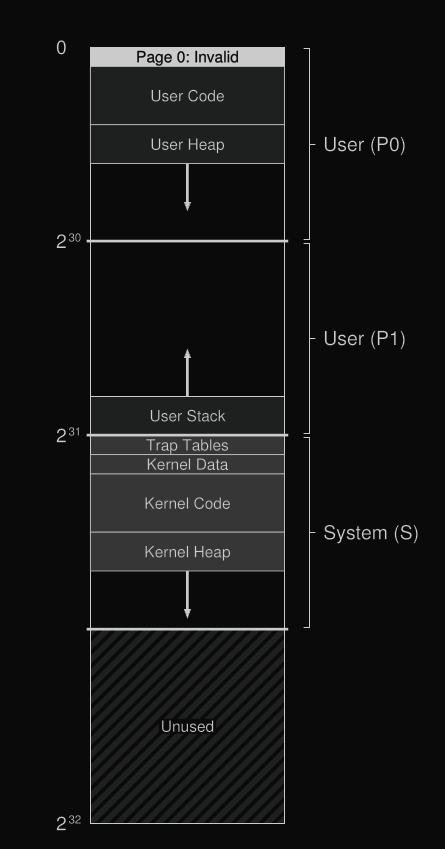
- Had a 32 bit virtual address space.
- Pages of 512 bytes, thus the offset was 9 bits and 23 bits for VPN in a virtual address.
- Upper 2 bits of the 23 bits were used to differentiate between the segments the page resided in.
- Lower half of the total address space was know as "process space" and was unique to each process.
- In the first half of this were the user programs and heap which grew downwards. The second half had the stack the grew upwards.
- The upper half of the address space is called system space and it is where the important OS code and data resides.
- No page table was used for the portion between the stack and the heap. They had base and bounds registers.
The process memory pages resided in the kernel memory section.
- The VAX paging system had no reference bit, so it was not possible to determine which pages were in use recently.
- To deal with memory hogs, the developers came up with segmented FIFO.
- Each process can keep a fixed number of pages in memory, also known as its Resident Set Size.
- Then the first page in RSS would be evicted.
- Then, to avoid FIFO performance, the developers came up with two second chance lists
that were used to store a global list of clean and dirty pages respectively.
- If the page is in the lists and the process faults on it, then we can simply pick the page off the list and give it to the process. If some other process requests it before that, however, then we need to swap it in from memory.
- VMS also had demand zeroing. Basically pages were zeroed out when they are needed, usually on a page fault for a heap page.
- Apart from that, it had Copy on Write. This copies the page memory only when it is written to. Otherwise, it only keeps a read-only reference to the original location in memory.
- Linux
- User space from 0x0 to 0xC0000000.
- Stack at the highest address.
- Lowest is forbidden invalid zero page.
- Following that is the user code, then user heap that grows to the higher address space.
- Addresses higher than that are kernel memory, logical and virtual.
- Logical is obtained from the kernel allocator
kmalloc. These cannot be swapped to disk.- Logical has the property that the physical memory and the logical memory are in one to one correspondence.
- Used for stuff like DMA etc. where contiguous mapping is preferred.
- Virtual memory exists and is allocated using the
vmallocfunction call.- This does not have contiguous memory.
- The reason this exists is because we need to have a large virtual memory space for the kernel.
- Not an issue on 64 bit machines.
- Sets up regular multi-level page tables for the structures. Four level.
- It allows for multiple page sizes, so the kernel has to support multiple page sizes.
- Linux also has a page cache hash table that allows it to service frequently used pages it tracks clean and dirty pages and a background process frequently writes them back to the responsible file (IO device/file/swap space).
- Linux uses 2Q replacement policy on a machine with very low memory. Two lists: active and inactive.
- When the page in the first (inactive) list is referenced again, it is sent to the active list.
- The active list is regularly pruned to be 2/3rds of the total cache size, helping with keeping the list fresh.
- Replacement is done from a page of the other list.
- Security is a focus, so ROP chains and code injections have mitigations ASLR and NX bits respectively.
- KPTI is kernel page table isolation so that users are not able to read it at all, only the bare minimum.
Concurrency
Basically like separate processes but having the same address space. This is helpful as it lets processes do better in terms of performance. Similar to a PCB, we now have a Thread Control Block for each of the process that keeps a track of the thread that is being executed. Also, there's overhead of switching page tables as the pages themselves remain the same.
One problem that does arise is the presence of multiple stacks in the address space that leads to a lot of fragmentation. However, this is fine as stacks are usually small except for programs that make heavy use of recursion.
API:
pthread_createcreates a thread, using the function to execute, the the properties of the thread, the thread struct itself, and the pointer to the args of the thread.pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void *), void *arg);pthread_joinwaits for the thread to finish execution and then joins back the main thread that spawned this thread.The program needs to be coherent. Hence no matter the order of execution, the end view of memory should be the same across all the threads.
int pthread_join(pthread_t thread, void **value_ptr);The second argument is the return value of the thread function.
- Another thing that is extremely important for parallelism is locks. These allow mutual
exclusion access to the critical section. We have
pthread_mutex_lockandpthread_mutex_unlockthat lock and unlock a mutex respectively. However, it also needs to be initialized properly. This can be done in two ways:- Using
PTHREAD_MUTEX_INITIALIZER(compile time). - Using
pthread_mutex_init()function call. - Corresponding destruction needs to be done with
pthread_mutex_destroy().
- Using
- There are other functions that exist for interacting with locks. These are
pthread_mutex_trylockthat returns failure if the lock is already held (instead of waiting on it), andpthread_mutex_timedlockreturns after the time specified or after the lock is held, whichever happens first. There are other things involved as synchronization primitives such as condition variables, this is achieved by binding the mutex with a condition variable. The APIs to do are as follows:
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);int pthread_cond_signal(pthread_cond_t *cond);
For either of the above to be called the lock has to be held on. Initializers for this follow a similar pattern as mutex.
More on Locks
Locks need to have mutual exclusion and fairness. Apart from that, another thing to take care of is performance.
One of the simplest ways to enable locking was to disable interrupts. This was simple enough as there was basically no complexity involved, and worked well for a single-processor system.
A non-exhaustive list of problems:
- privilege escalation
- doesn't work with multiple processors
- disabling interrupts for too long opens a separate can of worms.
Dekker's Algorithm: Only assumes atomic loads and stores
int flag[2];
int turn;
void init() {
// indicate you intend to hold the lock w/ ’flag’
flag[0] = flag[1] = 0;
// whose turn is it? (thread 0 or 1)
turn = 0;
}
void lock() {
// ’self’ is the thread ID of caller
flag[self] = 1;
// make it other thread’s turn
turn = 1 - self;
while ((flag[1-self] == 1) && (turn == 1 - self))
; // spin-wait while it’s not your turn
}
void unlock() {
// simply undo your intent
flag[self] = 0;
}
Another method is to use test-and-set to atomically set a flag and use a spin lock after that. It provides mutual exclusion but without any guarantee of fairness, since that depends on the thread scheduler. It may also lead to performance degradation as there are a lot of empty cycles being wasted in single threaded cores. However, with multiple CPUs they perform reasonably well as other threads are not starved and the thread scheduler doesn't have to kick in.
There are other instructions that can be used to make this work. One of them is the atomic compare-and-swap which checks the value first and then changes if it is equal to some specified value.
Another method to build a lock is to use a load-linked and store-conditional instruction pair. The first is just a regular load instruction, but the second one keeps a track of when the first one happened. The second one only succeeds if there was no intervening store to the address.
This way, we first load a value of 1 to the pointer. Then let's say another thread comes in and also loads a value of 1. Then when the first thread tries store-conditional, it'll fail as the value was updated between the load and the store.
Another method is to use the fetch-and-add instruction, which increments a value atomically and returns the old value. To build a lock over this, we simply have to give a constantly incrementing number as a ticket. Then we also have a global turn variable for all these threads that keeps incrementing at every unlock. Once the turn reaches the ticket, the lock is held by that thread, and when it unlocks, it's incremented again so that it can be given to the next thread. Thus, it ensures fairness.
Reducing Lock spinning overhead
A simple solution for that is to yield. Basically, anytime a thread that is in a locked state is executed, it simply yields its control back to the scheduler using some syscall that calls the thread scheduler again.
This also has problem.
- Context switches, even though less costly than utilizing entire time slices for spinning, is still too costly.
- Starvation still isn't dealt with. One thread may enter an endless yield loop while others repeatedly enter and exit the critical section.
typedef struct __lock_t {
int flag;
int guard;
queue_t *q;
} lock_t;
void lock_init(lock_t *m) {
m->flag = m->guard = 0;
queue_init(m->q);
};
void lock(lock_t *m) {
while(test_and_set(&m->guard, 1) == 1) ; //spin
if (m->flag == 0) { //lock not in use
m->flag = 1; //lock acquured
m->guard = 0;
} else {
queue_add(m->q, gettid());
m->guard = 0;
park(); // put the thread to sleep
}
}
void unlock(lock_t *m) {
while (test_and_set(&m->guard, 1) == 1) ; //spin
if (queue_empty(m->q)) {
m->flag = 0; // no need of lock anymore
} else { // don't unlock, just call the next thread
unpark(queue_remove(&m->q));
}
m->guard = 0;
}
To improve upon it, it's better to use queues that put the thread to sleep instead of making it yield. We use a queue to keep track of the threads that are waiting on a lock. We keep a guard on the queue (basically another spin lock) that keeps track of who's pushing and popping off the queue.
While locking, we acquire the guard, and then check if the main lock was acquired or not. If it wasn't, then we execute the thread and keep the lock acquired. If it was acquired, we will push the current thread to the queue and yield.
While unlocking, if there are no threads waiting on the queue, we unlock it, else we keep the lock active (so that no other thread steals it), and then let the next thread continue its invocation.
There is a race condition in this lock and unlock setup. We release the guard on the queue before we put the thread to sleep. When we are about to sleep, a context switch might happen. This can then lead to the first one being invoked right before sleeping, and when invoked it'll go to sleep, expecting to be woken up. And that'll fail because it was already woken up.
Linux uses a futex to avoid further overhead when locking and unlocking:
void mutex_lock(int *mutex) {
int v;
if (atomic_bit_test_set(mutex, 31) == 0) // bit was clear. we got mutex
return;
atomic_increment(mutex); // bit was set, we increment the futex value and
// wait on it
while (1) {
if (atomic_bit_test_set(mutex, 31) == 0) { // if futex happens to be unlocked
// revert the increment operation
// and take ownership
atomic_decrement(mutex);
return;
}
// have to wait to make sure the futex value we're monitoring is negative
// or locked
v = *mutex;
if (v >= 0) continue;
futex_wait(mutex, v); // if in between accessing v and calling this it was changed
// we return immediately and continue the loop
}
}
void mutex_unlock(int *mutex) {
// Adding 0x80000000 results in 0 if and only if there are no other threads waiting
// the futex is guaranteed to be locked rn
if (atomic_add_zero(mutex, 0x80000000)) return;
// There are other threads waiting, wake them up
futex_wake(mutex);
}
Over here, futex_wait puts the thread to sleep assuming the first argument is equal to the
second. If it is not, then it returns immediately.
Each thread is allotted a ticket number that is the last 31 bits of the atomic int. If the futex happens to be unlocked when we call the lock, we acquire it immediately and return.
Else, we enter a spin lock region. Here, we check for the lock bit again. If it is not set, then the lock is free to be taken. We revert the previous increment and return.
This is optimized for a single thread lock. In those situations the futex calls never happen and overhead is not there.
Condition Variables in mutex
These are useful when you want to wait for something to become true and wake up automatically. Shared variables and spin locks and other such stuff are very expensive here.
We have pthread_cond_t that allows you to declare a condition variable with a wait() and
signal() operations. The former puts the current thread to sleep on this condition variable,
the latter is called from some other thread to wake up the one that slept on it.
The POSIX API is like this:
pthread_cond_wait(pthread_cond_t *c, pthread_mutext_t *m)is the wait command for the threadpthread_cond_signal(pthread_cond_t *c)signals the thread to wake up.
We use a mutex in the wait call as follows:
- We assume the thread had locked the mutex before calling
wait - the wait call unlocks the mutex and releases it immediately, putting the thread to sleep
- when it wakes up, it locks the mutex again, and then continues its work.
We need the mutex to prevent race conditions and making threads sleep forever.
- Producer Consumer problem
This happens when you want to have a queue with multiple threads pushing into it and multiple threads popping out of it. Long story short, you need to use two condition variables, one for signalling the producers when a consumer has emptied the buffer and needs more, and the other one when a producer has filled the buffer and needs the consumers to take from it.
Apart from that, you need to keep a state variable to check if the buffer is full or not, and manipulate it accordingly. This check needs to be done in a while loop, because if can wake up multiple threads at once which can cause a data race.
Semaphores
These are something in between locks and condition variables. These are integers rather than a binary state like mutex. These allow the threads using it to have more context than just using a mutex.
We have sem_post() and sem_wait(). If the call to the latter results in a negative value, the
thread calling it is put to a wait. The call to the former is like a thread releasing a lock.
If there are more waiting threads (the value of the integer is negative) those threads are
woken.
A binary semaphore is basically a lock and a condition variable in one. It's just that,
sem_post can both be used as an unlock and a signal. Similar for sem_wait. It happens when
there are only two threads using it.
Semaphores are also used as an ordering primitive. That is because as said before, sem_post
can wake a thread up.
Finally, semaphore is just a lock and a condition variable along with a count. When the count is nonpositive, you wait on the condition, and then decrement the value when you finally stop waiting on it. When you release, increment and signal.
Concurrency Bugs
There are different kinds:
- Atomicity Violation (Event needs to be atomic but isn't)
- Order Violation (Order of events wasn't established properly)
- Deadlocks
The first can be prevented using locks. The second can be solved using condition variables.
The third can be prevented in many ways. The most common is to have a total ordering on the locking mechanism. However, this is often restrictive and needs great design consideration.
Another method is to make all the locks happen at once. This can be done by wrapping all the locks in a single lock and locking that before anything else. However, this leads to too coarse-grained locking and we also need to know which locks to lock ahead of time.
Yet another method is to not use locks at all and instead use a lock-free compare and swap mechanism for basically everything you want to do. However, this can be done only for simple things in practice.
Another mechanism would be just use the scheduler to avoid deadlocks and schedule processes such that they never conflict. Basically a ridiculous proposal.
IO and Storage Devices
IO devices are connected to the memory via PCI (peripheral component interconnect) bus containing high speed components like GPU, or via the peripheral bus (which has slower components like SATA, USB etc). These two buses join the memory bus containing the CPU and memory.
Device Drivers
We abstract out the details of the underlying device with the help of drivers to keep the implementation of higher level stacks like filesystem generic. How that's done depends on the hardware interface/ABI provided by the device.
- Storage Interface
We assume there are \(N\) sectors present in the disk and each sector is of size 512 bytes. Only a write to the most basic blocks are guaranteed to be atomic, otherwise multi-sector writes may end up as torn writes.
- Protocols for checking status
- Polling: We continuously check the status register and wait for it to be freed.
- Interrupts: Hardware raises an interrupt which resets the instruction vector to a predefined ISR or Interrupt Service Routine which handles the interrupt. This is not always ideal as context switching is involved. It is also possible that there is a huge burst of interrupts (a server receives tons of network packets)
- Protocols for transferring data
- PIO: The CPU explicitly copies the data from one place to another using software instructions.
- DMA: This is done by specialized devices called DMA engines. They do memory transfer in the background while the CPU continues to work, and raise an interrupt when they are done with the transfer.
- Communicating with the device
There are two methods to communicate with the device:
- Privileged instructions: These are only allowed to be used in OS privileges since they involve the use of privileged device registers.
- MMIO: These are registers that are mapped by the hardware to certain memory locations. Hence, accessing the memory region is the same as accessing the register.
Filesystem
The most basic block of a filesystem is the file itself. Each file has a low-level name, and in case of linux it is the inode number.
The second abstraction is the directory. This has a list of
(user-friendly name, machine-friendly name) pairs that are stored in a list. We can also store
other directories in this list, thus creating a directory tree. The root is the beginning of
the tree, which is / as the name.
On the user side of things, we have APis like open(), which opens a file for reading and
writing, and returns a file descriptor (a number special to the process and the file), and
also calls like read(), write() etc.
Inode holds the count of the number of links referring to it. That makes things like hardlinks possible. It als stores the blocks of the disk where the data is stored. Now ext- series filesystem has 10 direct block pointers, and 1 each of 1-level, 2-level, and 3-level indirection pointers.
Direct pointers point directly to the segment that stores data. This is used for fast access. Indirect pointers contain a linked list of pointers that allow multiple entries to be stored in the same pointer. This is used for very large files.
Apart from this, there might also be an extent associated with a pointer, which tells how many contiguous blocks of data are present. It might also be that the inode just stores one base pointer and one extent.
ext4 famously departs from the block pointer structure and uses 4 direct blocks with extents
to allocate. Further blocks are stored as an HTree.
All these filesystems also have an Access Control List. That allows them to decide if the user is capable of opening the file or not. This is again, stored as metadata in the inodes, and may be in a block or in some other form.
- Virtual File System
Any filesystem on linux has to implement a basic interface as dictated by the above thing. That later on uses those things to provide the common userspace APIs such as
open(),read(),write()etc.Yeah that's pretty much it. Everything else is just details in Linux.
- Journalling
Before doing anything to the file, whatever has to be done is written to a journal. That ensures that the file is able to restore its operation in case of a failure. Note that this has to be idempotent, if you do an operation, repeating it shouldn't be a problem. Only then will journalling work. This journal is of a finite size and is used as a circular buffer.
Apart from this, the filesystem also caches the writes into memory first and writes all of them together to reduce write overheads.
RAID devices
- Raid-0: Striping across multiple disks. Allows you to get more read and write bandwidth and helps boost disk perf.
- Raid-1: Mirroring across disks. Helps in having redundant information. This allows disk failure to be recoverable.
- Raid-4: Parity check: store the failure info of all the blocks in that row as a parity function in the last disk and get it if needed.
- Raid-5: Same as RAID-4, except parity blocks are rotated across the disks to remove the write bottlenecks while computing parities.
