branch predictors
Branch predictors and the basic idea behind how they work.
branch predictors
All of this is based on this talk by fedor pikus.
Branch Predictors
We can usually fit many operations in one clock cycle. So if all instructions were independent, we can in theory do like 5 or 6 instructions at once.
There are 2 types of dependencies in software: data dependency and conditional dependency.
Data dependency happens when you need the result of the previous computation in the current one. Solution: pipelining. Interleave the instructions for multiple iterations and it helps a lot. However, it might lead to Data Hazards.
However, this is all fun and games until the branch condition isn't satisfied. Those lead to Control Hazards. To prevent this, CPU have branch predictors.
Branch Misprediction
If the branch predictor is wrong, several things need to be done:
- All predicted stuff needs to be discarded/aborted. That means the pipeline needs to be flushed.
- New computations need to be started.
- Any results that were computed need to be undone. If it cannot be undone, it cannot be done speculatively.
Branchless optimizations
We can use bool + bool instead of
bool || bool to force both the branches to be
evaluated. If they are, then we know that the double branching
because of the short circuiting will not be problematic, since that
leads to double jumps and such. Not to mention all of the above too.
However, this does more work, so it may not be a nice thing to have
all the time.
Structure of a branch predictor
It has two buffers, a direction predictor and a branch target buffer.
The branch target buffer is a cache that has entries in the
format pc:jump for every single pc value possible. That
is
possible pc values. In the first invocation it actually stalls,
calculates and loads the address. In subsequent invocations it just
reads it off from there.
The direction predictor is also a table of sorts that has one of those counters for every single pc. Each time a branch is encountered, you fetch the counter value and predict accordingly. And later on update the result in the counter.
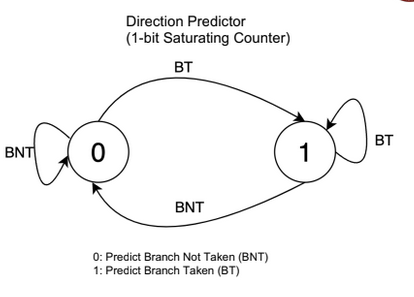
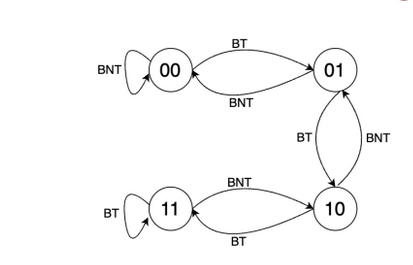
This is good for single branches like loops and if-else. However in case of nested branches performance can be improved by using something called as a GShare.
A global share history buffer register is a shift register that stores the values of the previous 32 branches. When we want to choose the index for the direction predictor, we first XOR pc with the gshare value and then use it. The branch target buffer indexing remains the same.
When we want to update the counter, we update both the counter and the gshare. We update the original counter, and then push back the bit in gshare.