Parsing in compilers
Fundamentals and basics of lexing in compilers, with various string algorithms.
Parsing in compilers
Learned a lot about parsing today. So much it was actually pretty interesting. A lot of notes were made.
Parsing
There are many kinds of parsers. All of them are supposed to take a Context Free Grammar (or rather, a restriction on it) and recognise programs that conform to it.
A CFG has a set of terminals called tokens. These are what form the bottom rung of the CFG rules.
These compose in a certain way to form rules called productions. A non-terminal is any other token that is not a terminal (i.e. not returned by the lexer) and is a particular order of other terminals or non-terminals in a specified order.
list -> list + digit | list - digit | digit
digit -> 0 | 1 | 2 | ... | 9A production is for a non-terminal if it is on the LHS of the rule, also known as the head. The RHS of the same rule is called the body of the production. A start-symbol is one which is where the parsing starts. A string is said to be derived from a grammar if we can make replacements in the start symbol many times by replacing a non-terminal with the body of the non-terminal's production.
A parse-tree is what is formed when you apply the production rule substitutions to derive a string. Needless to say, there can be multiple parse trees for a single string if the grammar allows it. Such grammars are called ambiguous.
Precedence and Associativity
This can be encoded in the grammar itself. It could lead to either shift-reduce or reduce-reduce conflicts in the parser. The latter must be avoided at all costs unless you're using a glr parser. The former is still ok on most occasions. If the grammar is ambiguous, then use
%precedencein yacc to specify the precedence order.Once again, even when there's no precedence conflict, you can have associativity problems. You can specify
%leftor%right(eg, equality of variables) for either of the two.If you want left associativity, write left-recursive grammar. Else write right-recursive grammar.
Sentential forms
At each step in derivation of the string, we make two choices.
- First is to choose which non-terminal in the current string to substitute.
- Second is to choose the production to replace it with.
Two common formats are leftmost and rightmost. Thus, we talk of left sentential and right sentential forms. Rightmost are also called canonical derivations.
Left Recursion
is what a left recursion is. Top down cannot handle left recursion. There is a generic method to convert left recursion to right recursion.
Algorithm:
- arrange non-terminals in some order …
- for
to
- for
to
- replace by the rules mentioned above where are current productions
- eliminate immediate left recursion in productions.
- for
to
Left factoring
Bunch common terms on the left side till you only have a single alternative of that kind.
Top Down Parsing
Do a DFS in the parse tree (preorder)
Find the leftmost derivation at each instant
Generally does recursive descent which backtracks
Special case is LL(k) which does predictive parsing based on a parse table.
for each production in
- for
to
- if is a nonterminal call corresponding function
- else if is the next symbol advance input
- else go back one token (yyless) and break
- if matches break;
- else current input position is saved
- for
to
First and Follow sets
Parsing is aided by FIRST and FOLLOW sets which allow the parser to choose which production to apply.
First is the set of terminals that begin strings when derived from
- If , that is also there in the first set
Follow is the set of terminals that can appear to the right of
- If then follow of contains
- If then follow of contains First - If also has in its first, then follow of also contains
- If
then follow of
contains follow of
- and is nullable then follow of contains follow of
Predictive parsing table for LL(1)
- for each production
- for each terminal in FIRST Table[$A$][$a$].add()
- if
in FIRST
- for each terminal in FOLLOW Table[$A$][$b$].add()
- if
$is in FOLLOW Table[$A$][$].add()
Now if a cell is empty after this then it's an error
- for each production
Conflicts due to the above
FIRST FIRST (can be solved by left factoring)
FIRST FOLLOW (combine terms on left so that decision is deferred, basically left factor) In this case however it is an instance of some sort of left recursion.
Bottom Up parsing
Reverse derivation happens from rightmost. Basically, we have the tokens and we combine or reduce them to non-terminals. Hence called LR parsing
A handle is a substring of the production that can be reduced into a non-terminal. This will always be at the top of the stack.
- Shift reduce conflicts appear when the handled can be reduced and another token shifted can also lead to a new reduction. Basically the tail of a production is also a reduction.
- Reduce reduce happens when two different lengths of the top can be reduced to something.
Simple LR or SLR
Shift and reduce, what else do I even say? Every token can be associated with a semantic value, which is like an action in Bison.
Shift reduce decisions are made by generating a set of states that keeps track of where we are in the rule.
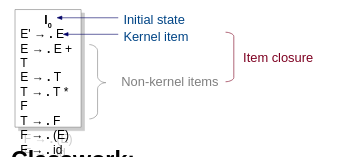
This is how we start.
If [A → α . X β] is in itemset I, then GOTO(I, X) is the closure of the itemset [A → α X . β]. For instance, GOTO(I0, E) is {E' → E ., E → E . + T}.
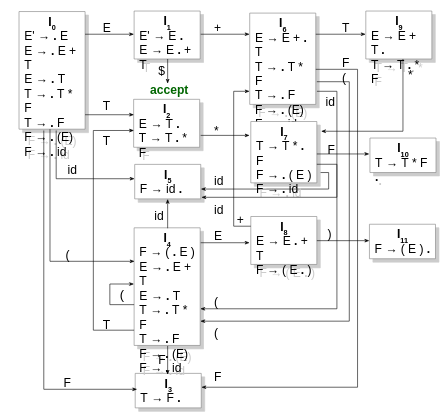
Depending on what we will encounter next, the automaton transitions.
How is the actual parsing done? We start with the initial state I0. We encounter a terminal and then go to the corresponding state in the automaton. Over there we see that the next token we got from the lexer either has a rule going from the current state to another state (shift), or is in the FOLLOW of the topmost token currently. This is checked via the dot in the states.
Shift-reduce happens when there is a transition from one state on encountering a term and it is also there in the follow of the same term for that state.
Reduce-reduce happens when you can go back to different states while reducing and more than one of them contribute to the same token in the follow of the current state.
Canonical LR or CLR
Parse with lookahead when creating the automaton. This allows for more precise parsing and lets you write more ambiguous grammar that lets you get better results and cleaner results or some shit like that.
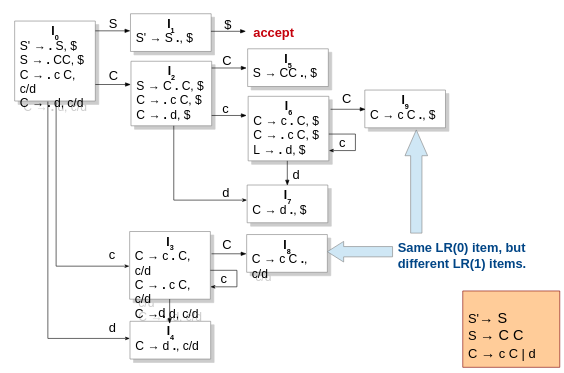
LALR
Same as CLR but merges states that are identical. Will not generate S-R conflicts but can generate R-R conflicts.
Syntax Directed Translation
This is the actions and attributes that we associate with the derivations/reductions happening during the parsing stage.
Types of attributes:
- Inherited: It is inherited from the parent node or the sibling nodes in the AST. Eg: scoping.
- Synthesized: It is taken from the children nodes of the AST. Eg: most of the parsing constructs.
If only synthesized attributes and actions are there, then any of the bottom-up parsers would work, eg. post-order traversal. There is a dependency graph of how that flows. However, regardless of the types of actions, there must not be a circular dependency in it.
Only using synthesized attributes is called S-attributed SDT. In most situations, however, it is too strict. We can allow attributes to flow from the parent and left siblings. This is called L-attributed SDT.
L-attributed SDT
Each attribute must either be:
- synthesized
- inherited
- For a production
with inherited attributes
computed by an action, the rule may use only
- inherited attributes from
- either inherited or synthesized attributes for
This is mostly only used with a top-down parser.
S-attributed SDT
These are used when doing bottom-up parsing. In fact, bottom-up parsing exclusively makes use of S-attributed SDTs. This is because it does not have the parent node at all. Midrule actions are basically resolved to empty non-terminals that allow the parser to treat it as a postfix SDT.